Transform PDFs into Searchable Data with olmOCR Integration
Happy to share about our integration with olmOCR technology, enabling instant conversion of complex PDF documents into structured, searchable data.
We've been working to solve one of the most challenging problems in document processing. Here's what's new:
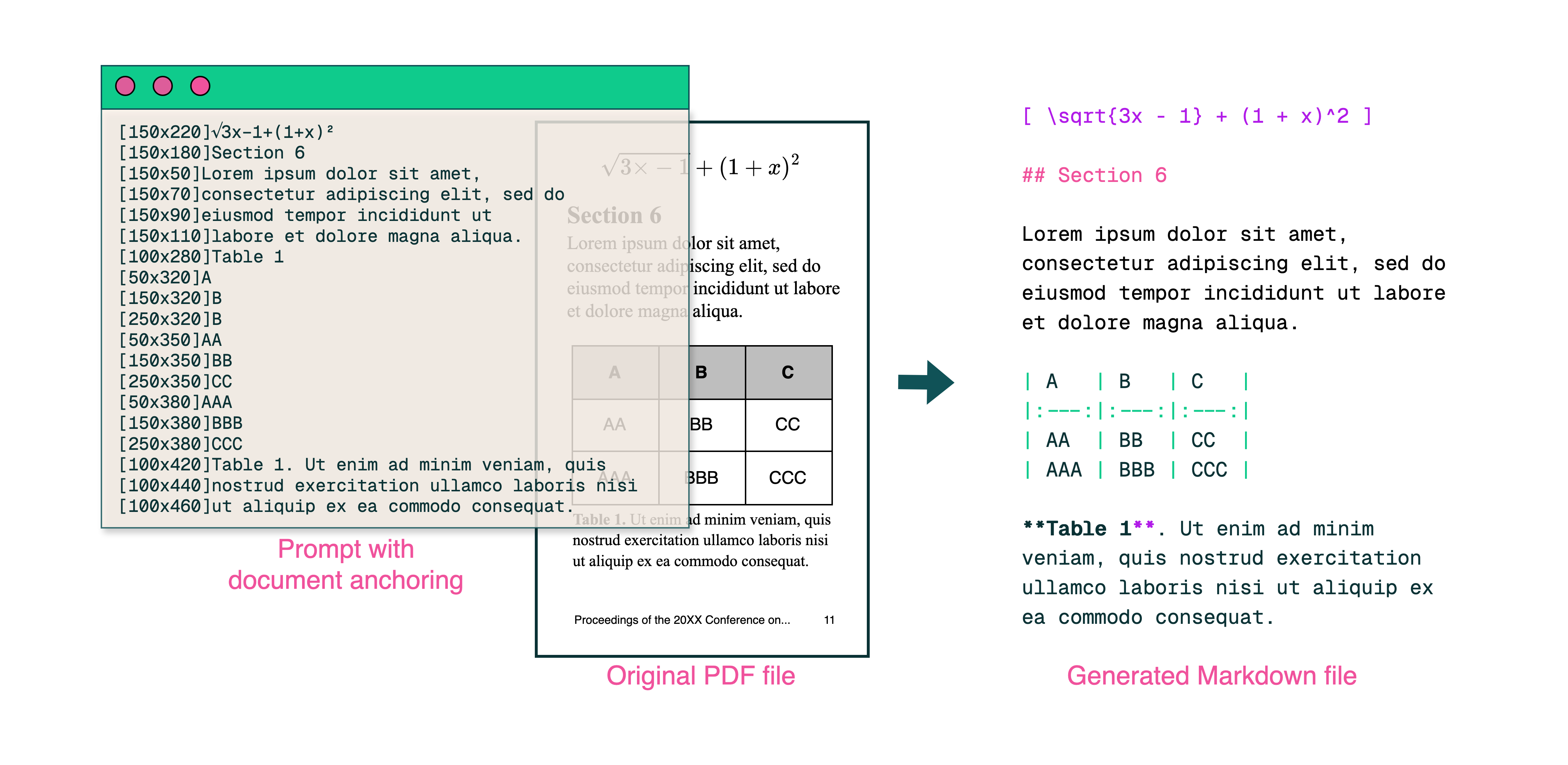
Vision Language Models for PDF Processing
We've integrated olmOCR's powerful toolkit that uses advanced Vision Language Models to transform even the most complex PDFs into highly accurate structured data, preserving both content and layout information.

Intelligent Document Understanding
Our system now leverages AI to understand the visual and semantic structure of documents, properly handling tables, forms, images with text, and multi-column layouts. The technology automatically extracts meaningful information while maintaining relationships between different document elements.
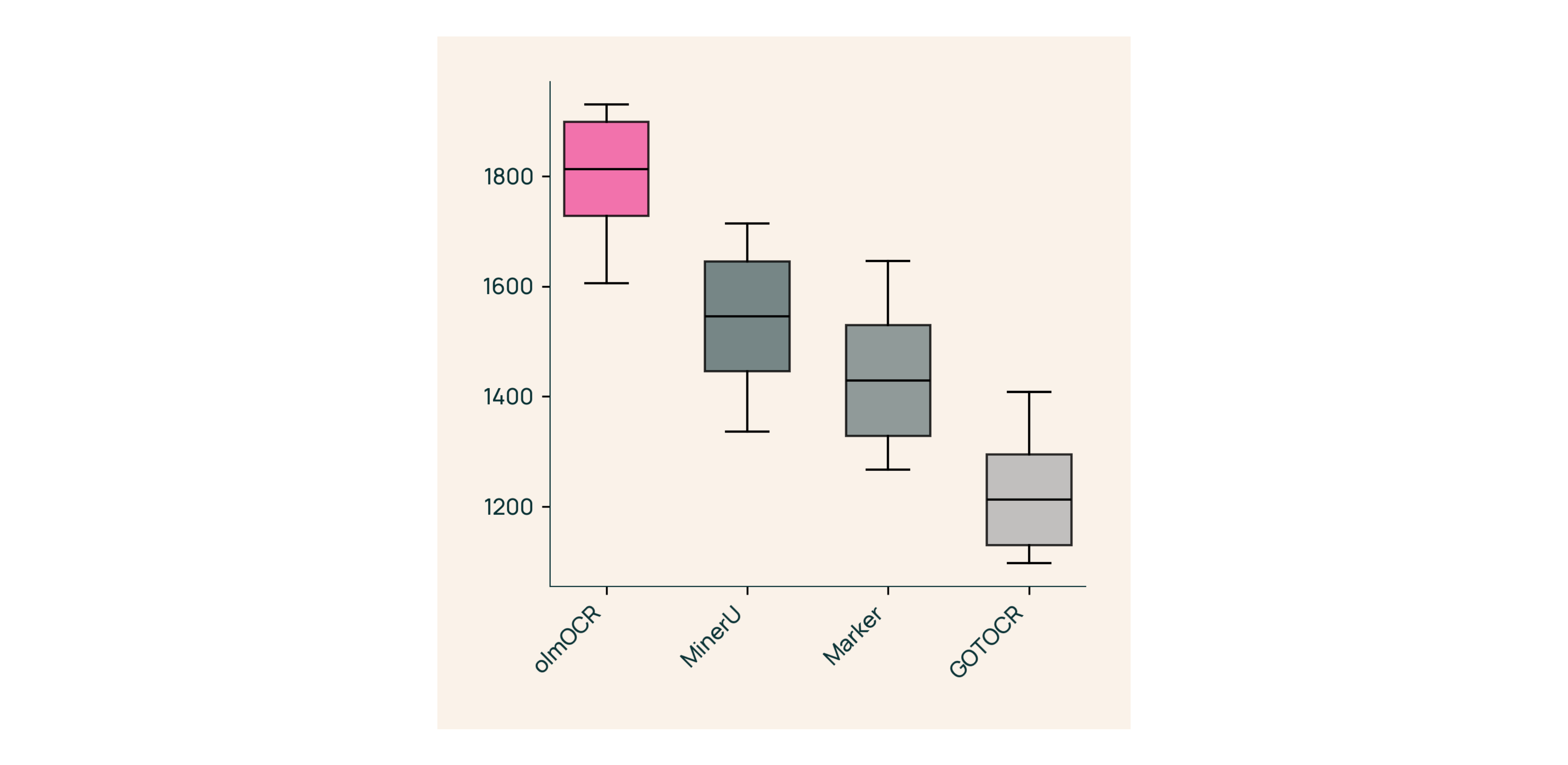
Flexible Output Formats
While our system handles the complex extraction process, you maintain full control over the output. Choose between structured JSON, markdown, plain text, or HTML formats depending on your specific needs and downstream applications.
Multi-Language Support
Our PDF conversion technology works across multiple languages and writing systems, accurately extracting text from documents in English, Spanish, French, German, Chinese, Japanese, Arabic, and many more languages.
What's Next?
We're developing specialized extraction models for industry-specific document types like financial reports, legal contracts, and scientific papers. We're also working on advanced search capabilities that will allow you to instantly find information across your entire document library.
Once again thank you for all your support and feedback. Our product is shaped by you. Feel free to reply to this email, we read every message.